
What is a great image? It’s just the previous image with more contrast and saturation, right (/s) ? But at some point, the contrast or saturation is too high. And what if the creator of the image didn’t want more contrast, what if a photographer wants his photo to look dull to convey an emotion? What if an image is desaturated on purpose? Is the best image the most realistic one, or the most pleasing one?
You can’t transform an image without changing the message it conveys. However, you can make this image more pleasing visually. In this article I detail how I built an algorithm to enhance images and what I learned.
Image enhancers
We’ve all used image enhancers. They may be among the most used algorithms in the world. Take a photo with your smartphone and it’ll be enhanced with an algorithm. What does “enhanced” mean? Well, it can include multiple things:
- Removing blur
- Removing noise
- Raising resolution
- Adjusting lighting, contrast and saturation
- Enhancing faces
- Reconstructing missing information (colors, degraded images…)
- Adding a filter, etc.
There are multiple ways to enhance an image. It can be done automatically with a simple mathematical analysis of the information in the image (“The sum of pixels is too low, it’s too dark, the brightness needs to be changed”). It can be carried out on the user’s decision with a simple mathematical analysis (“This image would be much better with a black and white filter”). And it can be done with deep learning (DL) algorithms, based on user’s decision or automatically.
However, when DL algorithms are used, they have one major constraint: they can be very slow to run on low-end devices.
An example of DL algorithm to enhance images is https://arxiv.org/pdf/1704.02470.pdf . In this paper, enhancing an image means improving its “color, texture and content” to make photos from mobile devices similar to photos from professional cameras. They combine multiple losses and use GANs to discriminate their “enhanced image” vs an already great “target image”. If the generator manages to enhance the image enough, the discriminator won’t notice the difference, otherwise you can train the generator based on the difference to make it better at fooling the discriminator. Basically, their goal is to do f(bad_image) = great_image. They need f. This is the goal of most DL algorithms to enhance images.
This is not exactly what I did.
Algorithm
In fact, I didn’t really want to improve images. I just stumbled upon an “aesthetic predictor” on Github.
It does what it says: it predicts how “aesthetic” an image is. So I used it on all my images, and it worked pretty well. The images with the highest score are indeed very great, and the images with the worst scores are quite unaesthetic. You can see some results here: http://captions.christoph-schuhmann.de/aesthetic_viz_laion_sac+logos+ava1-l14-linearMSE-en-2.37B.html
It’s based on AVA: “A largescale database for aesthetic visual analysis”.
Now.
- I know algorithms to change brightness / saturation / contrast / blur / sharpness / etc. of an image
- I know how to measure how aesthetic an image is.
So… Well I can transform an image once randomly, see if the result is better (aesthetic score improved), keep it if it’s better, or keep the previous image otherwise. And I can redo that again, and again, and again..
Add a decision tree on top of that, and you approximately have the algorithm I implemented. Each node is a bunch of transformations and I try new transformations on the best nodes of the graph.
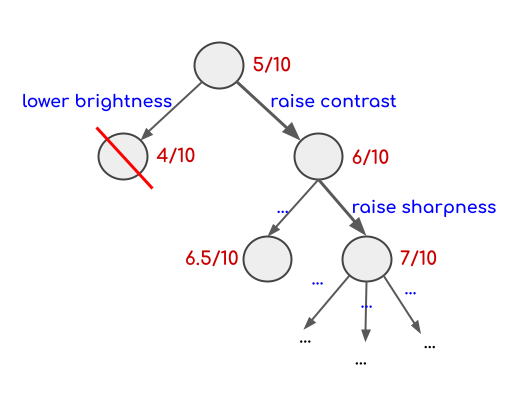
Pros
- You can decide on how to transform the image. With standard DL enhancers, it may be harder to control saturation / contrast / lighting / etc independently. With this algorithm it’s possible.
- You can scale the processing time the way you want, the algorithm can run for 5 seconds or 5 hours and continuously try new transformations
Cons
- With this specific aesthetic predictor, what “aesthetic means” isn’t clearly defined for photos, and it can include changing the content of an image if it’s a transformation the model has access to. If the model could remove an unaesthetic detail in an image, it would.
- The model is overall pretty slow as it constantly needs to transform and evaluate an image. The current version could, however, be improved, but it requires multiple seconds to get a good enough result with a middle-end GPU
Results
In this part you’ll get what I meant with the first section of this article. My algorithm has two modes, a “soft” mode and a “hard mode”. The soft mode only has access to some basic transformations on contrast / saturation / brightness. However, the “hard” mode can do much more stuff. Let’s start with some results of the soft mode:
Soft mode



Hard mode
Ok, same question as before, what is an “enhanced” image?
Is this image …:

… an enhanced version of this image?:

It’s just not the same image anymore. The “hard” mode is able to transform an image much more (posterize, solarize, invert, change hue, etc.). And, it can try to “enhance” an image by giving it a more artistic touch. I found these results quite interesting and I wanted to share them. Overall the algorithm is able to enhance most images but I think it has a bias towards making human faces darker. In theory this could be improved by designing an aesthetic predictor specifically for the task and by using a more accurate model…
That’s it!
Code
The algorithm is freely available as an extension for sd-webui:
or as a standalone in command-line with python:
Requirements
- An NVIDIA GPU with > 2GB VRAM (very slow on CPU)
- CLIP
- Pytorch
Models
- Aesthetic predictor: github.com/christophschuhmann/improved-aesthetic-predictor
- CLIP: github.com/openai/CLIP
You can also check Marques Brownlee’s video on how he evaluated smartphone cameras: https://www.youtube.com/watch?v=LQdjmGimh04 (and in fact he mostly evaluated the post-processed images, that is, the best “image enhancer” in modern smartphone cameras).
👏 If you want more articles like this! Thanks!