Construire un serveur de Deep Learning en 2020/2021

[UPDATE 2020/10/03: Prise en compte des nouveaux GPUs de Nvidia]
L’intelligence artificielle, à travers l’apprentissage profond, est une discipline bien établie. Les algorithmes utilisés progressent, mais ces algorithmes dépendent de machines bien physiques, nous allons voir comment construire un serveur d’apprentissage profond!
Qu’est-ce que c’est qu’un serveur? C’est une machine qui coûte à l’achat, qui consomme et coûte de l’électricité à l’usage, et qui utilise les logiciels que vous souhaitez sur le système d’exploitation que vous choisissez pour exploiter les composants que vous avez achetés.
Quel usage?
Première question à se poser: qu’est ce que l’on souhaite faire? Il est possible de faire de l’apprentissage profond sur à peu près n’importe quel ordinateur. Avoir des résultats proches de l’état de l’art sur un dataset comme MNIST est accessible même sur des processeurs de vieux téléphones. Sur CIFAR10, des ordinateurs portables bas à milieu de gamme suffisent.
Lorsque l’on souhaite quitter le bac à sable pour entrer dans le monde réel, dans lequel une image fait rarement 32*32 pixels ou quand on veut traiter des textes efficacement, il est temps de se poser la question de l’achat d’un serveur. De là, tout est imaginable, du petit serveur fait maison à 1000€ pour étudiants/débutants, au serveur Nvidia DGX/HGX à 150.000€ pour les sociétés du CAC40, en passant par le serveur de petite entreprise à 5000€.
L’ordinateur: La base
Vu que je sens que tout le monde qui lirait ceci ne l’a pas, voici la base concernant un ordinateur. Oublions écran, souris, clavier, pâte thermique, carte wifi etc.. Un ordinateur a besoin:
- D’une alimentation (PSU)
- D’une carte mère (MB)
- D’un processeur (CPU)
- De la mémoire (RAM)
- Du stockage (SSD/HDD)
- D’une carte graphique (GPU)
- D’un boitier (Case)
- De ventilateurs (Fans, pour le processeur et pour le boitier)
Lors de l’installation, le but du jeu, c’est de mettre les carrés dans les carrés et les ronds dans les ronds. La carte mère contient plein de “trous” (connecteurs / slots), faut mettre les carrés (composants / fils de composants) dedans, et faut la caser elle dans le boitier, ensuite on branche, on démarre et ça marche (cf plein de vidéos sur youtube pour l’ordre exact des opérations).
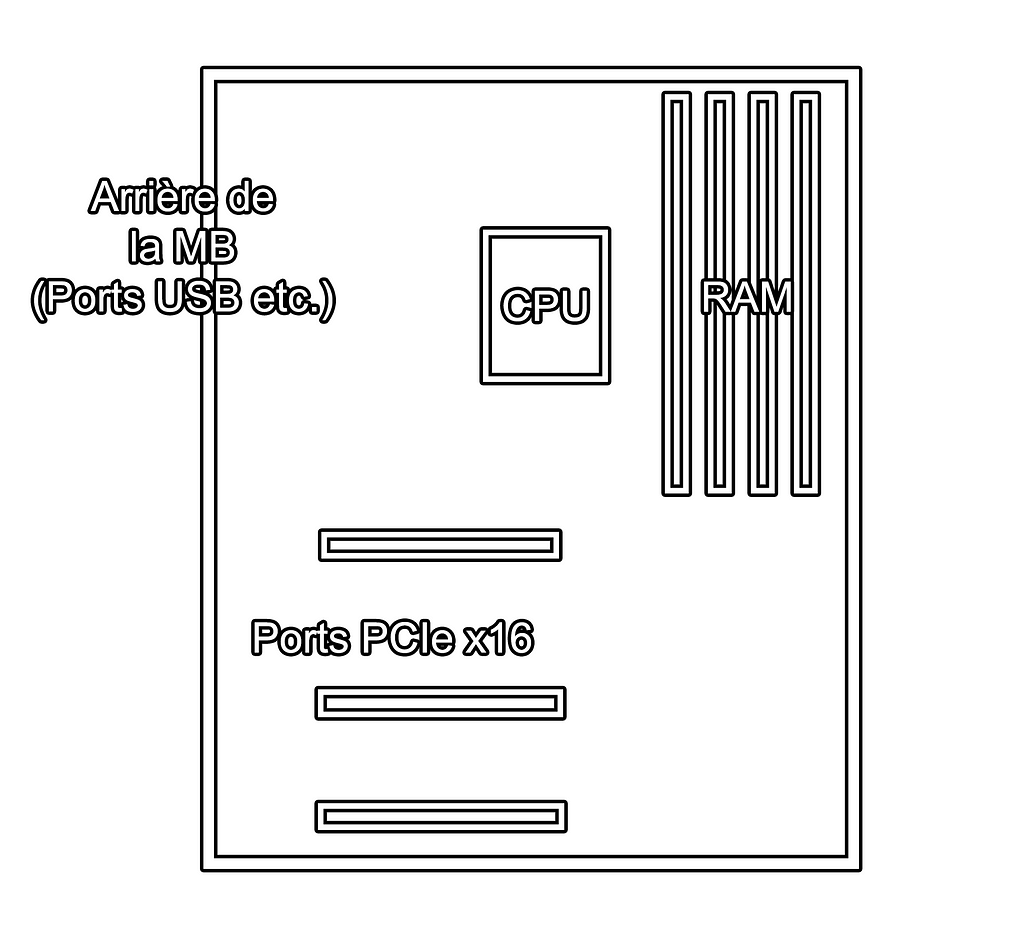
Il peut arriver qu’une carte graphique soit intégrée dans certains processeurs, cela ne dispense pas d’obtenir une carte graphique dédiée (à part).
Maintenant que vous savez ce dont vous avez besoin, la bonne question est de savoir qu’est ce que vous allez acheter pour chaque pièce de cet ensemble. Et c’est là qu’on revient à la première partie: tout dépend de votre usage. Je vais vous guider vers les éléments qualitatifs et limitants de chacune de ces parties, et ensuite il reviendra à vous de trouver, fluctuations des prix étant, la moins chère pour votre usage, selon l’époque à laquelle vous lirez ceci.
Le nombre de carte graphique
Une machine avec un seul GPU sur tout son cycle de vie peut se faire à 1000€, une machine qui pourrait aller jusqu’à 4 GPU mais avec les mêmes composants que la première se fera à 2000€ (sans les 3 autres GPUs évidemment). Tout dépend de votre capacité à estimer vos besoins sur 5ans.
Première étape donc, demandez vous combien de GPU vous souhaitez, et souhaiterez. Vous êtes étudiant? Ce sera un ou deux. Vous êtes une petite entreprise? Entre 2 et 4. Une grande société? Entre 4 et 8. Evidemment, c’est important car passer de 1 à 2 GPU, avec le même GPU, ça permet de doubler la puissance de calcul sur énormément d’usage, sans avoir à racheter une machine.
Davantage de GPU = Besoin de davantage de ports PCIex16 physiques sur la carte mère, = Limitation sur choix du CPU (tous ne gèrent pas 4 GPUs),= Augmentation de la puissance de l’alimentation.
Pour comprendre cela c’est simple, un GPU a besoin d’un emplacement PCIe, le CPU doit pouvoir communiquer avec le GPU via le port PCIe, et les GPUs sont très consommateurs en énergie.
Quoi qu’il arrive, l’objectif d’un build de deep learning c’est de créer un bottleneck sur le(s) GPU(s), c’est à dire de limiter le temps de calcul à la seule puissance du/des GPU(s), et non au CPU, non à la mémoire, non à la lecture sur le disque dur etc.. Si vous avez 4 GPUs mais que votre processeur tournait déjà à 100% avec deux, félicitations vous avez deux décorations supplémentaires dans votre boitier (mais ça fait cher le tuning).
Pour 2 GPUs, avec 1s CPU=>GPU1, 1s CPU=>GPU2, et 1s (GPU1+GPU2), vous avez 3s de calcul. Avec 4 GPUs vous passerez à 1s CPU => GPU(i) x4, et 1s (GPU(i)x4), soit 4+1=5s. Vous avez un bottleneck CPU, il faut changer le code ou acheter un nouveau CPU, pas de nouveaux GPU. +67% de temps de calcul, +100% de puissance de calcul.
Pour 2 GPUs, avec 0.1s CPU => GPU(i) et 2.8s (GPU1+GPU2), vous avez 3s de calcul. Pour 4 GPUs, vous aurez 3.2s de calcul, +6.7% de temps de calcul et +100% de puissance de calcul.
L’opération CPU => GPU est une opération de préparation des données, de transfert, mais cela peut aussi inclure la lecture sur le disque en cas d’un bottleneck disque etc. A noter que le pire des cas d’avoir +100% de temps de calcul avec +100% de puissance de calcul, ça revient au même que de laisser la config à 2GPU tourner plus longtemps. Et enfin, avoir 100% de calcul disponible en plus ne signifie pas une division par deux du temps d’entrainement puisque cette augmentation est parallèle est que les algorithmes ne suivent pas forcément une loi linéaire sur la donnée temps_entrainement = f(puissance_parallèle).
Evidemment, même si le build est important pour éviter des bottlenecks ailleurs que sur le GPU, les algorithmes utilisés le sont tout autant.
Le couple processeur / carte mère
La base d’un ordinateur c’est de déterminer sa gamme, et celle-ci est encadrée par le couple processeur / carte mère. Les processeurs ne sont souvent associables qu’à un nombre très restreint de cartes mères. Les deux fabricants de processeurs sont Intel et AMD, et chacun a différentes gammes, en allant du low cost et grand public au marché des serveurs high-end. AMD est le fabricant à privilégier en terme de ratio qualité/prix. Heureusement, des outils existent, et notamment le site PC Part Picker qui vous permettra d’éviter les incompatibilités CPU/MB.
Vu qu’on s’intéresse à la puissance, on commence par le processeur. Il doit avoir au strict minimum 4 cœurs 8 threads en 2020. Vous pouvez monter jusqu’à 16 coeurs 32 threads, et davantage si vous savez que vous en aurez besoin. Les prix vont de 100€ à >4000€. La règle est simple, moins c’est cher, moins on peut en faire quelque chose. Evidemment il faut que ce choix soit adapté au nombre de GPU, 4 coeurs pour 4 GPUs ça n’est pas concordant (bottleneck CPU), et 32 coeurs pour 1 GPU non plus. Ça n’est pas une règle, tout dépend des usages, mais l’idée générale sauf cas spécifiques est là.
Donc on place le seuil à ce qu’on veut faire, et on prend le moins cher. Pour des usages optimisés de deep learning, le processeur n’est que peu utilisé en comparaison du GPU, un processeur pour un serveur de deep learning ne devrait pas excéder 400€ avec 8 coeurs. Certains processeurs threadripper de AMD (orientés serveurs) ont l’avantage d’être peu chers, le TR1920X est à 270 +/- 30€ avec 12 coeurs, mais la carte mère associée (et donc le socket) ne sont ni compatibles avec les nouvelles (très hautes) gammes de threadripper TR3XXX ni avec les gammes Ryzen simple (3/5/7/9) grand publiques et moins énergivores. Le prix du processeur s’analyse en ayant conscience de l’ensemble des prix des composants qu’il conditionne. Mais la gamme des processeurs Ryzen simples ne peut pas gérer 4 GPUs, c’est là que vous faites un choix. Soit vous voulez 4 GPUs tôt ou tard, et donc vous devez prendre une gamme serveur de AMD / Intel, et donc si c’est AMD un Threadripper (“Ryzen Threadripper/2000/3000”), soit non, et vous prenez du grand public, et donc si c’est AMD un Ryzen (“Ryzen 3/5/7/9”).
- Facteurs qualitatifs du CPU: Nombre de threads, Consommation en watt
- Facteurs limitants du CPU: Nombre de PCIe supportés (et donc de GPU)
Une fois le CPU choisi, vous êtes limités par la carte mère. Même avec un CPU qui sait gérer 4 GPUs, toutes les cartes mères compatibles n’ont pas 4 PCIe slots. Je vais résumer le PCIe:

{kind=link}
PCIe (Peripheral Component Interconnect Express): C’est un port présent sur la MB pour rajouter des composants à un PC, comme un port USB, mais avec des spécificités. Un port PCIe peut être qualifié par 3 données:
- une version (v3 / v4 / v5), plus c’est élevé, plus la capacité de transfert de données est importante entre la carte mère et le composant,
- une forme physique (x1, x4, x8, x16), plus c’est élevé, plus le port est long sur la carte mère
- une connexion électrique (x1, x4, x8, x12, x16), plus c’est élevé, plus la capacité de transfert de données est importante
Est-ce que c’est important? Sur la capacité de transfert pour du deep learning, à peu près non. Un V3 x4 (bas de gamme) est à 4Go/s théorique, donc en général non-limitant pour transférer un ordre de grandeur de 128 images de 1000*1000*3, soit ~400Mo en 0.1s de la RAM vers le GPU.
Un GPU va sur un PCIe x16 physique. Donc votre MB doit en avoir autant que de GPU que vous souhaitez utiliser. Vérifier la présence de PCIe x16 se fait visuellement sur la carte mère, donc c’est facile, par contre la donnée de connexion électrique n’est pas toujours simple à trouver. A noter: les cartes mères n’ont pas à être compatibles SLI (multi GPU nvidia) pour des usages de deep learning (c’est principalement utilisé pour le gaming).
- Facteurs qualitatifs de la MB: Dans l’absolu, pour du deep learning, il n’y en a pas vraiment, le haut de gamme est surtout moins limitant, mais regarder les avis des personnes qui ont la même MB est important
- Facteurs limitants de la MB: Nombre de PCIe supportés (et donc de GPU), RAM supportée (en quantité et en compatibilité), wifi intégré (sinon il faut être près d’un routeur/switch et avoir un câble ethernet)
Le GPU
Les libs utilisées en deep sont principalement Pytorch et Tensorflow, lesquelles sont principalement basées sur CUDA, CUDA fonctionne principalement sur les GPU NVIDIA, donc sauf à chercher les chemins compliqués, vous achèterez un GPU NVIDIA.
Il y a trois types de refroidissements. Soit “blower”, l’air est aspiré, passe sur le GPU et sort à l’arrière du boitier. Soit à ventilateur et l’air est envoyé dans le boitier, soit à watercooling. Pour un GPU ou maximum deux GPU milieu de gamme, peu importe. Au delà, il faut prendre un “blower” sinon l’air renvoyé dans le boitier créera une surchauffe. Donc là encore, il faut anticiper, une fois acheté vous ne “pourrez plus” changer. Pourquoi n’y a t-il pas que des blowers? Parce qu’ils sont plus bruyants principalement, ce qui est moins agréable pour des usages gamers par exemple.
Quatre gammes, à vue de nez:
- Bas de gamme: GTX 1050(Ti) / 1060(Ti) / 1070(Ti) / 16xx(S)
- Milieu de gamme: RTX 3080 / RTX 3070 / RTX 2060(S)/2070(S)
- Haut de gamme: RTX 3090/ RTX2080Ti
- Très haut de gamme: Titan RTX / V100 / certaines Quadro etc.
Ce que vous devez regarder principalement c’est le prix, la mémoire, et la puissance. 2 GO suffisent pour des petites images, 4 Go permettront de faire davantage, 8 Go pour des usages réels (RTX3070), ~11 Go (RTX3080 / GTX1080Ti / RTX2080Ti / GTX TITAN) pour des usages de recherche et plus de 20 Go (RTX 3090 / Titan RTX) pour des usages spécifiques. A titre personnel, en terme de ratio qualité/prix je recommande les RTX de 8~11 Go pour à peu près tous les usages. L’évolution des scores en apprentissage profond se fait davantage grâce à des avancées qualitatives algorithmiques que quantitatives hardware. Ces avancées qualitatives peuvent être basées sur 500 GPUs/TPUs chez Google, mais une fois qu’eux ont utilisé cette puissance pour faire cette avancée, nous n’avons pas besoin de tout refaire, et nous pouvons en général reproduire les résultats ou les adapter à nos usages sur un GPU de 8Go en entrainement, et 2Go voir moins en inférence.
Remarque: C’est de cette façon que nous avons fais AI Magic Mirror ou Melanomia. Le réseau de neurone à la base est un Efficient Net, réseau complexe issu de l’optimisation sur une énorme puissance de calcul de Google, adapté à notre usage sur des RTX de 8Go, converti et utilisable sur navigateur web.
/!\ IMPORTANT: Les cartes RTX sont dotées de “tensor cores” qui leur permettent de traiter efficacement du FP16. Les calculs de deep learning sont (étaient) en général faits en FP32, mais une telle précision est souvent superflue, ainsi traiter efficacement du FP16 via des libs comme APEX permet approximativement de doubler le batch et d’augmenter la puissance de calcul. Une carte RTX 2060S de 8Go de mémoire bien utilisée peut s’avérer plus intéressante qu’une GTX1080Ti de 11Go.
====
[UPDATE POUR RTX30XX: De nouvelles cartes de Nvidia ont été diffusées avec un ratio performance/prix meilleur que l’ancienne génération. Bien que surprenant de prime abord, ces résultats sont à pondérer pour des usages strictement deep learning ainsi qu’avec un prix évoluant selon l’offre et la demande. Des informations en détail peuvent être trouvées => ici <=. Pour résumer, aux prix annoncés, la RTX3080 et la RTX3070 donneraient un gain performance/prix relatif de 40% en rapport avec le meilleur ratio performance/prix de l’ancienne génération (RTX2070Super). Evidemment si les prix montent de 20% pour la nouvelle génération et baissent de 20% pour l’ancienne, les ratios qualité/prix sont à recalculer]
====
Des ordres de grandeur de puissance (les RAMs peuvent varier): une GTX 1050 Ti peut entraîner un modèle sur CIFAR10 en 1h. Une RTX 2060S est plus puissante qu’une GTX 1080. Une RTX 2070S est équivalente à une GTX 1080 Ti, et peut atteindre 90% top5 sur Imagenet en 10h (moins avec un code plus optimisé, de la superconvergence etc.). Les RTX 2080Ti sont 1.5x plus puissantes qu’une RTX2070S, mais le prix fait souvent x2, et elles nécessitent davantage de puissance électrique. Les Titan RTX sont proches des RTX 2080 Ti, leur principal avantage est la mémoire supplémentaire. Les RTX30XX dominent les autres cartes en terme d’efficacité mais consomment davantage d’électricité que leur “équivalent” RTX20XX, un gain de +40% de perfs/prix_achat légèrement compensé par +10% de coût électrique.
Une fois que vous avez ciblé la mémoire, je vous renvoie sur ce graphe du ratio performance/prix de Tim Dettmers (MAJ RTX30XX). TLDR: si vous êtes en galère de tune prenez une 1660Ti (~300€), sinon prenez une RTX2060S(~400€) ou une RTX3070 (~650€), sauf si vous avez les besoins d’une RTX3080 (~850€), sauf si vous avez besoin de la RAM d’une RTX 3090 (~1800€). Les prix du neuf peuvent faire +/- 20% en fonction des humeurs, de la présence ou non d’une pandémie mondiale et autres aléas. A -40% c’est une arnaque.
{kind=link}
- Facteurs qualitatifs du GPU: FLOPS, durée de garantie, consommation
- Facteurs limitants du GPU: Quantité de mémoire
La mémoire
La mémoire non graphique peut être limitante selon les usages. Les mémoires ont des générations (DDR3, DDR4, DDR5), la DDR4 est actuellement celle utilisée sur les machines récentes. Il faut absolument prendre 8Go ou plus, idéalement 16Go en laissant des espaces pour aller à 32Go (pour étudiants), 32Go si on sait qu’on a l’usage (pour petite entreprise), et au delà pour des cas particuliers.
Par exemple il est possible (mais rarement utile) de charger tout un dataset dans la mémoire. Si on a 30.000 images de 500x500x3 octets, ça donne 21Go, il faut donc prendre 32Go de RAM. Ainsi, vos algorithmes n’auront aucune latence liée à la lecture sur l’espace de stockage. Mais il y a peu de chances que vous ayez un bottleneck ici si vous utilisez un SSD.
En général, chaque carte mère a une liste des RAM compatibles qu’il est préférable de consulter avant l’achat pour éviter les mauvaises surprises. Les caractéristiques qualitatives d’une RAM sont principalement sa vitesse (2133Mhz ou davantage pour une génération DDR4) et sa latence, mais ces données ne sont pas très importantes en deep learning. Ne mettez pas 50€ de plus pour avoir du 4000Mhz avec des néons.
- Facteurs qualitatifs de la RAM: Vitesse, latence
- Facteurs limitants de la RAM: Quantité de mémoire
Le stockage
Nous sommes en 2020, vous allez donc prendre un SSD. Ici c’est très simple, un SSD de 2To coûte environ 300€ +/- 100€ (voir davantage). Le principal concernant les SSD est que vous ayez la place suffisante pour y mettre au moins un dataset, celui que vous êtes en train d’utiliser, ainsi que vos applications et votre OS. Imagenet2012 pèse 140Go pour 1M300 Images. Coco2017 est à 50Go pour 125k images. En imaginant que vous ne sortiez pas trop des sentiers battus, 500Go à 1To de SSD suffiront. 2To pour des usages spécifiques.
Les caractéristiques délivrées par les constructeurs sont souvent extrêmement théoriques. Fiez vous uniquement aux benchmarks trouvables en ligne, et sur ces benchmarks ce qui vous intéresse c’est principalement la vitesse de lecture.
Dans le détail, il existe plusieurs type de SSD. Le NVMe M.2 est un ensemble de spécification à privilégier concernant le format et la connectique, les SSD NVMe ont alors une forme de barrette et s’intègrent directement sur un port M.2 spécifique de la carte mère. Les SSDs sont faits de cellule, ils peuvent stocker 1bit/cellule, ou 2, ou 3, 4 voir 5. Chaque nombre est associé à un type de SSD: SLC (Single-level cell) = 1 bit / cellule, MLC = 2bit/c, TLC = 3bit/c, QLC / 4bit/c.
Si certains SSD sont très chers avec la même quantité de mémoire, c’est parce qu’ils garantissent une meilleure vitesse de lecture et surtout d’écriture grâce à l’architecture des cellules. De manière générale, du plus cher au moins cher on a les SLC puis MLC puis TLC puis QLC. Vu qu’on s’intéresse surtout à la vitesse de lecture en deep learning, des QLC peuvent bien nous suffire.
- Facteurs qualitatifs du SSD: Vitesse de lecture puis vitesse d’écriture
- Facteurs limitants du SSD: Taille, format
En plus du SSD, vous pouvez prendre un HDD pour stocker l’ensemble de vos datasets à froid, quand vous ne vous en servez pas. 4To = 110€ +/- 20€.
Les HDD nécessitent des connexions SATA sur la carte mère. Les câbles de connexions sont en général fournis avec la MB.
Le boitier
On en vient à bout! Je vous recommande principalement de prendre un boitier utilisé par quelqu’un qui a une config proche de la votre, ça vous évitera d’avoir à vérifier toutes les caractéristiques.
Il faut que le boitier ait un format qui puisse contenir le format de la carte mère. Les formats sont par exemple ATX, eATX, etc. Si vous utilisez PC Part Picker avec le filtre de compatibilité, vous n’aurez pas de problème à ce niveau. Il faut que le boitier ait suffisamment de port d’expansion pour l’ensemble des ports PCIe, ces ports font le lien entre l’arrière des composants sur le PCIe de la MB et l’arrière du boitier. Pour 4 GPUs il faut 8 ports d’expansion sur le boitier, sinon moins.
- Facteurs qualitatifs du boitier: Les ventilateurs inclus, le filtre à poussière pour le PSU, l’esthétique (sauf s’il va dans une cave), etc.
- Facteurs limitants du boitier: Capacité à tout caser dedans (longueur GPU, hauteur ventilateur CPU etc.), ports d’expansion, nombre de baie pour HDD/SSD…
L’alimentation
Vous prenez l’alimentation qui permet de tout alimenter, et une marge supérieure de 100W. Vous calculez avec ceci: https://outervision.com/power-supply-calculator . Si vos composants consomment 850W, vous prenez une alimentation de 1000W.
Si on reprend la base, votre serveur consomme de l’électricité. La quantité d’électricité utilisée se détermine en Watt, votre machine consommera de l’ordre de 400 (1GPU) à 2000Watt (4GPU) en usage. Si vous consommez 1000Watt (~3GPUs) pendant 1heure, vous consommez 1kW*1h = 1kWh, ce qui coûte environ 0.16€ +/- 0.04€ en France. Si vous entraînez la moitié de l’année, ça fait 365*24/2 = 4380 kWh soit environ 700€ (233€/GPU). Ces ordres de grandeur peuvent énormément varier selon le GPU, le CPU et les algorithmes utilisés, rares sont ceux qui maintiennent un usage à 100% du GPU sur tout l’entrainement.
Dans le détail (mais pas trop), chaque alimentation a une classe de qualité qui va de rien, bronze, silver, gold, platinum à titanium. Et chaque classe permet de consommer moins d’électricité, de l’ordre de 10% entre bronze et platinum. Donc sur une facture d’électricité à 500€/an pour usage du serveur, ça représente 50€. Sur un prix de l’électricité qui augmente à moyen terme et pour un PSU garantie 5/10ans, on recommande vivement de prendre du titanium quand cela est possible, si le surcoût est de 200€, je vous laisse évaluer.
Egalement le PSU peut être No/Semi/Full Modular, ce qui correspond grosso modo à votre capacité à brancher les câbles comme vous voulez dessus. No-Modular = tous les cables sont pré-branchés et non-débranchables, full-modular tous les cables sont branchables/débranchables à volonté et semi est entre les deux.
L’idée de la connectique d’un serveur est simple. Chaque composant doit faire transiter des données/instructions, et pour cela il a une connexion avec la MB, et chaque composant requiert de l’électricité, et pour cela soit la MB le lui fournit (c’est le cas du processeur par exemple), soit le PSU le lui fournit. Les GPUs auront tous une connexion PCIe avec la MB pour les données, mais ils auront aussi tous une connexion différente avec le PSU pour être alimentés. D’où les joies de cette science appelée “cable-management”.
- Facteurs qualitatifs de l’alim: Classe (Titanium > Platinum > Gold > Silver > Bronze), Full-modular > Semi-modular > No-modular
- Facteurs limitants de l’alim: La puissance délivrée doit suffire à tout alimenter
Les ventilateurs
Et le pire pour la fin: les ventilateurs. Votre serveur consomme de l’électricité. Mais puisque rien ne se perd, (rien ne se crée), tout se transforme, et que le virtuel se base toujours sur du réel, l’électricité consommée ne se transforme par qu’en jolis résultats sur un écran mais également en chaleur. Et puisqu’un ordinateur n’est pas une machine à faire fondre du métal en premier usage, il faut évacuer cette chaleur.
Il y a trois zones à cibler. La première est déjà faite, il s’agit du GPU. A peu près tous les GPUs ont des ventilateurs déjà associés, donc on s’en occupe pas.
Fiuu, on a bien bossé… allez une pause!
[…]
Reste le CPU et le boitier. Le CPU a besoin d’un ventilateur dédié car il émet énormément de chaleur en comparaison des autres composants (sauf GPUs) qui utilisent souvent exclusivement un refroidissement passif. Et le boitier a besoin de mettre toute cette chaleur, du CPU et du reste, à l’extérieur.
Le choix se fait principalement sur des caractéristiques de bruit et de capacité à évacuer la chaleur. Les AIO (All In One Watercooling) sont généralement à éviter car peu durables et souvent associés à des problèmes de fuites, d’installations etc.., sauf si vous en trouvez qui soient bien notés sur le long terme. Les ventilateurs Noctua sont souvent associés à un bon ratio (efficacité)/ (beauté*bruit), donc à privilégier si vous faites une config pour faire du deep learning, mais pas si vous faites une config pour avoir des jolis couleurs.
En ce qui concerne la configuration dans le boitier, le flot d’air doit aller de l’avant de votre PC, vers l’arrière et vers le haut. Le nombre de ventilateurs dépend principalement de la configuration, 2 ventilateurs de 120mm et celui du CPU peuvent suffire pour une petite configuration. Tout cela dépend également de la pièce dans laquelle vous êtes, de votre climat etc. Les suédois ont moins de problèmes que les méditerranéens on ne va pas se le cacher.
- Facteurs qualitatifs des ventilos: Quantité d’air++, Bruit- -
- Facteurs limitants des ventilos: Le format doit être compatible avec le CPU, la taille du fan du CPU doit marcher avec le boitier ainsi que la RAM, la taille des fans doit aller dans les emplacements sur le boitier
Conclusion
Voilà, il n’y a plus qu’à acheter les composants qui respectent ces configurations. Je recommande d’utiliser PC Part Picker, de se fixer sur une config, de voir ses limites, de changer les composants, de voir les limites, de rechanger les composants etc.. une config ne se fait pas en un coup, c’est un jeu précis d’optimisation de maximisation de qualité avec minimisation de prix. Idéalement chaque composant que vous choisissez doit avoir été déjà noté par d’autres positivement (plus de 50 évaluations à 4/5).
En cas de doute, vous pouvez publier votre configuration sur le subreddit “PC Master Race” ou demander de l’aide à des personnes qui ont déjà cette expérience.
J’espère que ce guide sera utile! Je n’ai pas monté 50 configurations, mais j’ai fais le tour de tous les tutoriels sur le sujet, et vu que ça m’a pris 300 ans je me suis dis que tenter de résumer tout ça en un article pourrait simplifier la vie à certaines personnes. Hésitez pas à le dire si c’est le cas!
EXEMPLE DE CONFIGURATION
(parce que vous avez la flemme de tout faire, ne mentez pas!)
Attention, tout le monde peut se tromper, trouver des composants incompatibles etc.. On ne peut être sûr à 100% qu’en usage réel, et vu que je n’ai pas fais les configurations suivantes, je ne peux pas garantir leur fiabilité.
Low cost (1200€): https://fr.pcpartpicker.com/list/89mN7T
Middle end (4000€): (todo si demandé)
High end (10.000€): (todo si demandé)
N’hésitez pas à prendre des composants d’occasion si vous avez un petit budget, surtout si vous avez une garantie associée. Déjà c’est mieux pour la planète, pour le portefeuille, et concernant des composants comme les SSD, les GPU (qui s’usent souvent peu en bon usage), la RAM (parfois garantie à vie), ou l’alimentation (parfois garantie 10ans), ça peut réellement valoir le coup.
Des questions? N’hésitez pas. Besoin d’une expertise? Contactez nous!
Liens annexes:
- Choix du GPU et Meilleurs GPU: https://timdettmers.com/2019/04/03/which-gpu-for-deep-learning/
- Puissance absolue des GPUs: https://i1.wp.com/timdettmers.com/wp-content/uploads/2019/04/performance_RTX.png
- Puissance par dollar des GPUs: https://i1.wp.com/timdettmers.com/wp-content/uploads/2019/04/performance_per_dollar_RTX.png
- Faut-il payer cher le SSD? /!\ Il n’y a que l’usage gamer de testé : https://www.youtube.com/watch?v=4DKLA7w9eeA
- Le guide de Jeff Chen: https://medium.com/the-mission/how-to-build-the-perfect-deep-learning-computer-and-save-thousands-of-dollars-9ec3b2eb4ce2
- Calculer la puissance requise: https://outervision.com/power-supply-calculator
- Trois chaines youtube clés pour aller dans le détail sur chaque sujet: https://www.youtube.com/user/LinusTechTips/videos (et Techquickie), https://www.youtube.com/user/GamersNexus/videos et https://www.youtube.com/user/Jayztwocents/videos
{kind=link}
{kind=link}
Support us 💙
You can follow us on Twitter to show support and to see all news (no tweet-spam, only news), or here on Medium.